논문 번역 파이프라인이 잘 돌아가고 있었다. 용어 추출하고, 레이아웃 분석하고, 번역하고. 그런데 '잘 돌아간다'와 '빠르게 돌아간다'는 다른 문제다. 순차적으로 실행되던 두 단계를 병렬로 바꾸고, Claude Code headless 모드의 stream-json 파싱이 깨지는 문제를 수정한 이야기다.
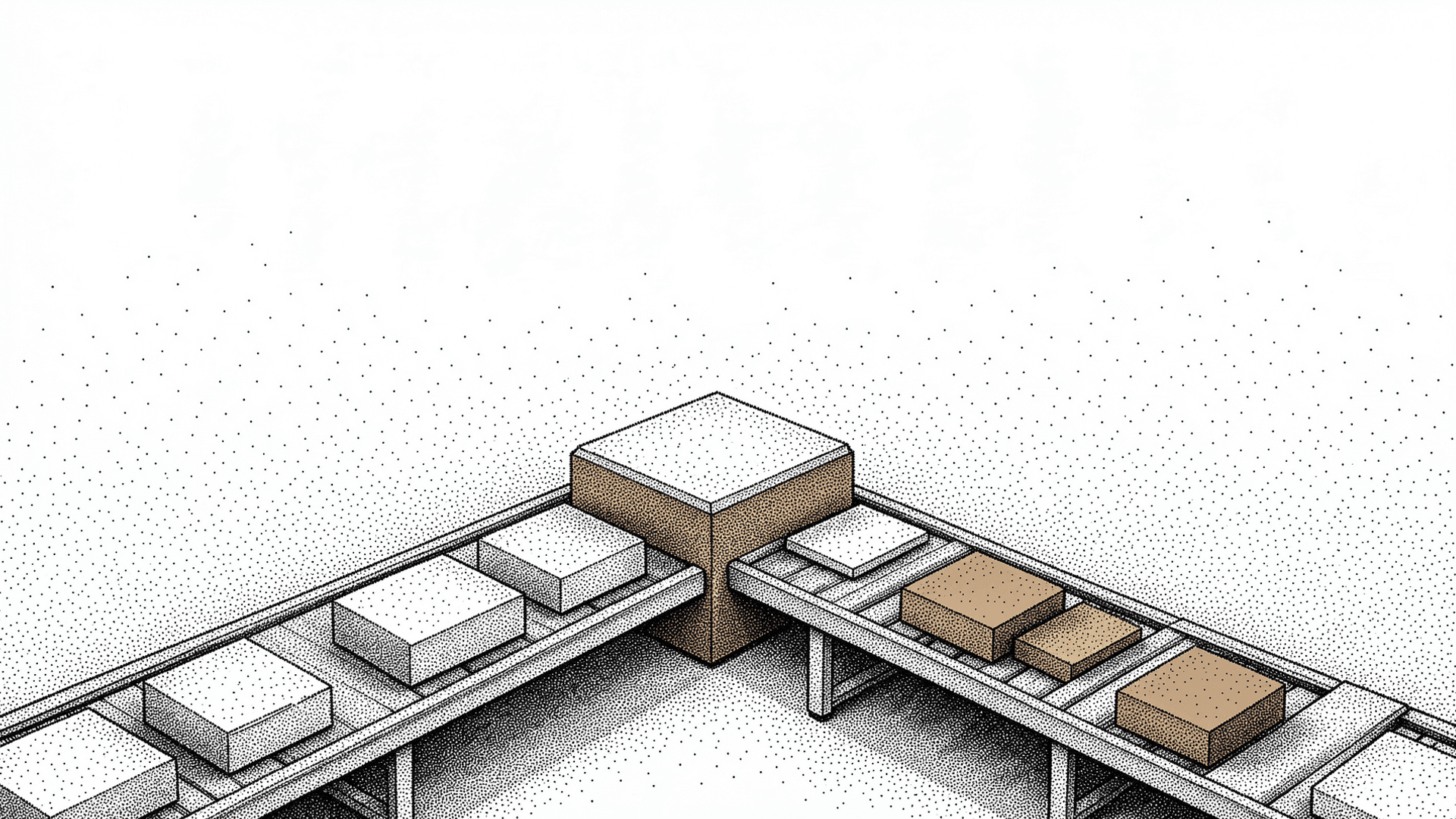
번역 파이프라인에서 용어(glossary) 추출과 BabelDOC 레이아웃 분석은 완전히 독립적인 작업이다. 용어 추출은 Claude Code headless로 PDF에서 전문 용어를 뽑아내고, 레이아웃 분석은 BabelDOC이 PDF의 구조를 파악한다. 서로의 결과를 참조하지 않는다.
그런데 이 두 작업이 순차 실행되고 있었다. 용어 추출이 끝나야 레이아웃 분석이 시작됐다. PDF 하나에 용어 추출 30초, 레이아웃 분석 20초라면 총 50초. 병렬로 돌리면 30초면 끝나는 일이다.
Python의 asyncio.gather()를 쓰면 독립적인 비동기 작업을 간단하게 병렬로 실행할 수 있다.
코드 변경은 3줄이다. 하지만 체감 속도 차이는 크다. 두 작업 중 더 오래 걸리는 쪽의 시간만 기다리면 되니까, 실질적으로 한 단계가 공짜가 된 셈이다.
용어 추출은 Claude Code를 headless 모드로 돌려서 처리한다. 이때 --output-format stream-json 옵션으로 진행률을 실시간 추적하는데, 어느 날부터 파싱이 깨지기 시작했다.
원인은 Claude Code의 stream-json 출력 형식 변경이었다. 기존에는 stream_event 키로 이벤트를 구분했는데, 업데이트 이후 type 필드에 assistant와 result로 구분하는 방식으로 바뀌었다.
stream-json 파싱을 고치면서 작업 로그(task logs) 추적 기능도 함께 넣었다. headless 실행 중 stdout에서 단계별 진행 기록을 남기도록 했다. 이전에는 Claude Code가 뭘 하고 있는지 끝날 때까지 알 수 없었는데, 이제는 '용어 추출 중... 15/30 용어 발견' 같은 로그가 실시간으로 찍힌다.
vLLM을 uv run --no-sync vllm serve로 시작하고 있었다. --no-sync는 실행 전에 패키지를 동기화하지 않는 옵션인데, vLLM 패키지가 업데이트되면 wheel 파일이 404로 날아간다. 결국 --no-sync를 제거하고 매번 동기화하도록 바꿨다. 실행 속도보다 안정성이 중요한 경우다.
번역 없이 용어만 뽑고 싶을 때가 있다. 새 논문의 전문 용어를 미리 확인하거나, 용어 사전을 관리할 때 쓴다. translate-paper 에이전트에 '용어 추출 전용 모드'를 추가해서 번역 단계를 건너뛸 수 있게 했다.
'작동하는 것'에서 '빠르게 작동하는 것'으로 넘어가는 과정은 대부분 이런 식이다. 거창한 아키텍처 변경이 아니라, 순차 실행을 병렬로 바꾸고, 깨진 파싱을 고치고, 로그를 추가하는 작은 변경의 누적이다. 3줄 바꿔서 20초를 아꼈다. 논문 100편 번역하면 33분이다.