자막 생성 파이프라인을 CLI로 잘 쓰고 있었다. 화자 분리, 음성 인식, 텍스트 교정까지 한 번에 돌아가는 꽤 괜찮은 도구였는데 문제가 하나 있었다. 나만 쓸 수 있다는 거다. 터미널을 열고 Python 스크립트를 실행해야 하니 팀원에게 "이거 써봐"라고 말하기가 어려웠다.
그래서 웹 UI를 붙이기로 했다. 파일 올리면 진행률 보여주고 SRT 다운로드할 수 있는 간단한 페이지. 이전에 만든 Persistent Worker HTTP 서버 위에 엔드포인트 몇 개만 추가하면 될 줄 알았는데, 예상보다 삽질이 많았다.
처음에는 n8n 워크플로우로 빠르게 만들었다. n8n의 웹훅 노드가 HTML 폼을 서빙할 수 있어서 파일 업로드 페이지를 만들고, 받은 파일을 GPU 서버로 전달하는 구조였다. 프로토타입은 금방 나왔다.
그런데 수백 MB짜리 동영상 파일을 올려보니 n8n이 OOM으로 죽었다. n8n은 워크플로우 실행 중 데이터를 전부 메모리에 올린다. 텍스트나 JSON 정도는 문제없지만 700MB 동영상 파일은 감당이 안 됐다. 로코드 도구의 한계가 여기서 드러났다.
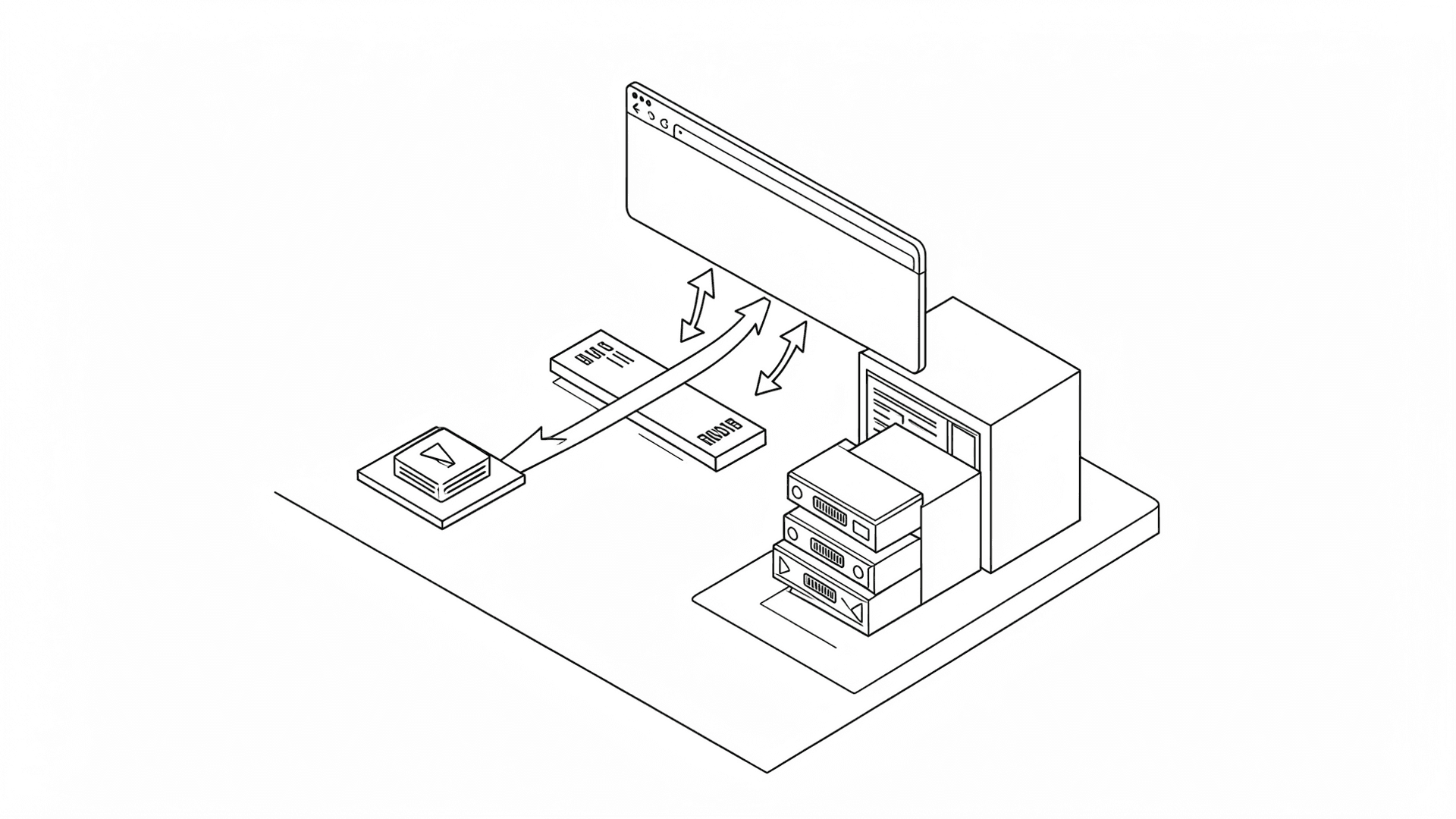
해법은 명확했다. 대용량 파일은 n8n을 거치지 않고 브라우저에서 GPU 서버로 직접 보내야 한다. n8n은 HTML 페이지만 서빙하고 실제 데이터 처리는 GPU 서버가 전담하는 BFF(Backend for Frontend) 구조로 바꿨다.
Traefik IngressRoute에서 경로별로 라우팅을 나눴다.
/webhook/* 경로는 n8n으로. HTML 페이지 서빙 전용/api/* 경로는 StripPrefix 미들웨어를 거쳐 GPU 서버(8891 포트)로 직접Cloudflare Tunnel이 앞단에서 HTTPS를 처리하고 Traefik이 내부 라우팅을 담당하는 구조다. 브라우저 입장에서는 같은 도메인(asr.museck.com)에 요청하지만 경로에 따라 다른 서버로 분기된다.
자막 생성은 몇 분씩 걸리는 작업이다. 동기 HTTP 요청으로는 타임아웃이 날 수밖에 없어서 Task 기반 비동기 처리 패턴을 적용했다. WebSocket까지 갈 필요 없이 폴링으로 충분했다.
POST /transcribe/upload으로 파일 업로드. taskId를 즉시 반환GET /transcribe/status/{taskId}로 진행률 폴링. stage와 progress 필드로 현재 단계 표시GET /transcribe/download/{taskId}/{filename}으로 완성된 SRT 파일 다운로드파일 업로드에서 OOM을 방지하려면 청크 단위로 디스크에 써야 한다. FastAPI의 UploadFile을 1MB씩 읽어서 바로 파일에 쓰는 방식이다.
@app.post("/transcribe/upload")
async def transcribe_upload(
file: UploadFile = File(...),
password: str = Form(""),
):
task_id = uuid.uuid4().hex[:12]
work_dir = Path(tempfile.mkdtemp(prefix=f"transcribe_{task_id}_"))
# 1MB씩 읽어서 디스크에 직접 쓰기 (OOM 방지)
with open(file_path, "wb") as f:
while chunk := await file.read(1024 * 1024):
f.write(chunk)
task = TranscriptionTask(task_id=task_id, work_dir=work_dir)
asyncio.create_task(_run_transcription_pipeline(task))
return {"taskId": task_id, "status": "processing"}asyncio.create_task()로 파이프라인을 백그라운드에서 실행하고 taskId만 바로 돌려준다. 클라이언트는 이 ID로 상태를 폴링하면 된다.
GPU 서버는 디스크가 넉넉하지 않다. 동영상 원본, 추출한 WAV, 생성된 SRT가 쌓이면 금방 차버린다. 그래서 파이프라인 각 단계가 끝날 때마다 불필요한 파일을 삭제하는 전략을 썼다.
async def _cleanup_old_tasks():
while True:
await asyncio.sleep(300) # 5분마다 체크
expired = [
tid for tid, t in _tasks.items()
if t.status in ("success", "error")
and time.time() - t.created_at > 3600
]
for tid in expired:
t = _tasks.pop(tid)
if t.work_dir and t.work_dir.exists():
shutil.rmtree(t.work_dir, ignore_errors=True)브라우저에서 GPU 서버로 직접 요청을 보내려면 CORS 설정이 필요하다. 처음에는 allow_origins=["https://asr.museck.com"]으로 정확히 설정했다. 로컬에서 테스트하면 잘 됐다.
배포하고 나니 안 됐다. n8n 웹훅이 서빙하는 HTML 페이지의 origin이 null로 찍히는 경우가 있었다. Cloudflare Tunnel을 경유하면서 일부 요청의 origin 헤더가 비정상적으로 들어온 것이다. 결국 allow_origins=["*"]로 풀었다. 보안적으로 이상적이진 않지만 내부 도구라 감수할 만했다.
웹 UI를 만들면서 한 가지 기능을 더 추가했다. 화자가 2명 이상 감지되면 화자 라벨이 포함된 SRT와 미포함 SRT를 둘 다 생성하는 것이다. CLI 시절에는 --no-speaker 플래그로 선택했는데 웹에서는 플래그 개념이 어색하니까 그냥 둘 다 만들어서 다운로드 링크를 두 개 제공하기로 했다. 사용자 입장에서 훨씬 편하다.
YouTube 다운로드 타임아웃도 잡아야 했다. yt-dlp로 긴 영상을 받으면 5분 넘게 걸릴 수 있는데 아무 제한 없이 두면 태스크가 무한 대기에 빠진다. asyncio.wait_for(timeout=300)으로 5분 제한을 걸었다.
Worker 자동 복구도 넣었다. 파이프라인 실행 중 worker 프로세스가 죽으면 _ensure_workers_ready()로 재시작을 시도한다. 다만 GPU가 이미 다른 작업 중이면 재시작이 실패할 수 있어서 그때는 사용자에게 에러를 돌려준다. 완벽한 장애 복구는 아니지만 대부분의 일시적 문제는 자동으로 넘어간다.
CLI 도구를 웹으로 열어주는 건 생각보다 고려할 게 많다. 대용량 파일을 어디서 받을지, 비동기 작업을 어떻게 추적할지, CORS는 어떻게 풀지. n8n 같은 로코드 도구로 프로토타입은 빠르게 만들 수 있지만 대용량 데이터를 다루는 순간 직접 라우팅이 필요해진다.
결국 각 컴포넌트가 잘하는 일만 맡기는 게 답이었다. n8n은 HTML 서빙, GPU 서버는 데이터 처리, Traefik은 라우팅. 역할을 명확히 나누니 OOM도 사라지고 구조도 깔끔해졌다.